AI提示词收藏
经典论文解读
开源仓库推荐
📚联邦学习如何助力AI产品环保?揭秘减少35%碳排放的奥秘
type
status
slug
summary
tags
category
icon
password
Date
联邦学习如何让AI产品更环保?全生命周期碳排放深度解析
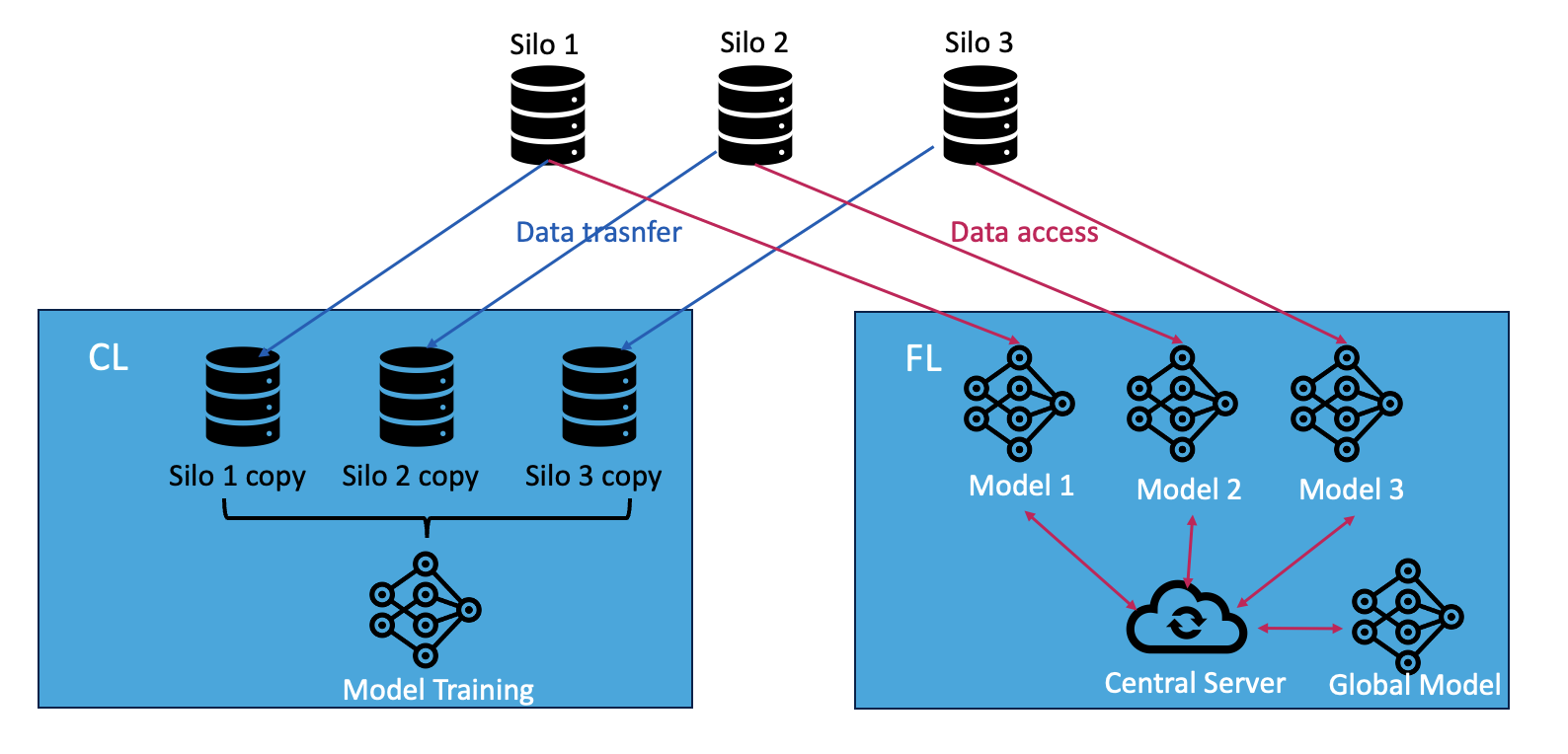
(图1:联邦学习与集中式学习的数据处理方式对比)
摘要
随着全球隐私保护法规的加强,**跨孤岛联邦学习(Cross-Silo FL)**正在成为企业AI开发的新趋势。这项技术通过分布式协作训练模型,既保护数据隐私,又能减少数据重复存储带来的碳排放。本文通过微软Azure云平台的真实实验数据,首次揭示了联邦学习在AI全生命周期中的环保优势——相比传统集中式学习,跨孤岛联邦学习可减少高达35%的碳排放,尤其在大规模数据场景下表现突出。
关键词:可持续AI、跨孤岛联邦学习、碳排放评估、分布式计算
一、AI发展的环境代价:GPT-3训练的警示
信息通信技术(ICT)行业占全球碳排放的2-3%,其中AI模型的训练能耗尤为惊人。以GPT-3为例:
- 耗电量:1,287兆瓦时,相当于121个美国家庭年用电量
- 碳排放:约500吨二氧化碳,等同400次巴黎-纽约往返航班
- 隐形成本:数据中心冷却用水量相当于3个标准游泳池

(图2:Azure云平台上的跨孤岛联邦学习架构)
二、联邦学习的环保突破
2.1 隐私与环保的双重革命
传统集中式学习需要将数据集中到统一服务器,带来两大问题:
- 隐私风险:数据集中存储易受攻击
- 环境负担:数据重复传输存储增加碳排放
跨孤岛联邦学习的创新之处在于:
- 各参与方(如医院、银行)保持数据本地化
- 仅交换模型参数更新,避免原始数据流转
- 通过分布式计算降低单点能耗压力
2.2 全生命周期碳足迹分析框架
研究团队提出创新评估模型,涵盖AI产品六大阶段:
阶段 | 碳排放来源 |
数据存储 | 硬盘类型、冗余备份策略 |
数据传输 | 网络能耗强度(0.06kWh/GB) |
模型训练 | GPU利用率、集群规模 |
通信开销 | 参数同步频率与数据量 |
内存管理 | 动态内存分配策略 |
部署维护 | 模型更新迭代频率 |
三、实验结果:环保优势的量化证据
3.1 训练阶段对比

(图3:不同规模数据集下的训练表现)
- 小数据集(1.2GB):联邦学习因通信开销多排放15%
- 中数据集(12GB):两种方式碳排放基本持平
- 大数据集(120GB):联邦学习减少28%碳排放
3.2 全生命周期对比

(图4:包含数据传输存储的整体环境影响)
关键发现:
- 集中式学习的数据迁移碳排放占总量的40-60%
- 联邦学习的分布式特性减少数据冗余存储达75%
- 在120GB场景下,整体碳减排效果达35%
四、企业级解决方案:智能数据管理系统

(图5:可持续数据管理系统的三层架构)
4.1 系统核心功能
- 智能请求分析:LLM自动匹配历史相似需求
- 动态资源分配:根据数据特征自动选择最优计算集群
- 联邦分析引擎:支持隐私保护的跨部门数据洞察
4.2 实施效果
- 减少重复模型开发70%以上
- 降低数据存储需求50-80%
- 缩短项目启动时间从周级到天级
五、未来展望:绿色AI新范式
本研究揭示的三大趋势:
- 边缘计算融合:5G网络下设备端训练优化
- 智能节能策略:动态调整通信频率的算法
- 碳足迹可视化:企业级碳排放监测仪表盘
研究团队正在开发的开源工具包已集成:
- Azure/GCP/AWS碳排放计算器
- 联邦学习通信优化模块
- 数据冗余智能检测系统
结语
当AI技术席卷全球,环保不再是可选项而是必答题。这项研究证明:通过跨孤岛联邦学习+智能数据管理的组合拳,企业可以在保护隐私的同时,实现运营成本与环境效益的双赢。在即将到来的AI 2.0时代,技术创新与可持续发展的深度融合,正在开启绿色计算的新纪元。
https://arxiv.org/abs/2312.14628